Fehlerdiagnose und Lösungsansätze — Optimierung des Outbox-Patterns mit Debezium und PostgreSQL
Durch die praktische Erfahrung in unseren Projekten haben wir mit der Zeit viel über die Tücken des Outbox-Patterns gelernt. Dessen erfolgreiche Implementierung mit Debezium und PostgreSQL erfordert ein reibungsloses Zusammenspiel vieler verschiedener Komponenten. Alle Rädchen müssen ineinander greifen, um eine einwandfreie Funktion zu gewährleisten. Das macht das Debugging besonders anspruchsvoll.
In diesem Lab stellen wir einige hilfreiche Tools und Lösungen für häufig auftretende Fehlerquellen und Probleme vor. Zunächst wollen wir aber auf einige Details der Funktionsweise von Debezium im Zusammenspiel mit PostgreSQL eingehen. Insbesondere werden wir die Replikationsfunktionalität von PostgreSQL erläutern, die die Debezium-Kafka-Konnektoren nutzen, um Events direkt aus der Datenbank abzurufen, ohne auf periodische Abfragen oder manuelles Polling angewiesen zu sein.
Falls das Outbox-Pattern oder Debezium neu für dich ist, haben wir deren Funktionsweise in einem separaten Lab vorgestellt.
Replikationsfunktionalität von PostgreSQL
Replikation auf PostgreSQL
Die Replikationsfunktionalität in PostgreSQL ermöglicht es, Daten in Echtzeit von einer PostgreSQL-Datenbank auf eine oder mehrere andere Datenbanken zu kopieren.
PostgreSQL verwendet Write-Ahead-Logging (WAL), um die Konsistenz und Persistenz von Transaktionen zu gewährleisten. Jede Daten-Änderung wird zuerst mit WAL protokolliert, bevor sie in die Dateien geschrieben wird, welche die eigentlichen Tabellen und Indizes enthalten. Dadurch kann PostgreSQL den Zustand der Datenbank wiederherstellen, falls es zu einem Absturz oder Stromausfall kommt.
Mit der Einführung von PostgreSQL 9.0 wurde erstmals die physische Replikation eingeführt. Dabei werden die WAL-Dateien vom primären Datenbank-Server an eine Replikat- oder Empfängerdatenbank gesendet und dort wieder angewendet. Allerdings ermöglicht dieser Ansatz nur die Replikation von ganzen Datenbanken. Um die Einschränkungen der physischen Replikation zu überwinden, wurde mit PostgreSQL 10.0 die logische Replikation eingeführt. Neu können auch nur einzelne Tabellen veröffentlicht werden.
Die logische Replikation folgt dem Publisher/Subscriber-Prinzip. Um Daten zu replizieren muss zunächst eine Publikation (Publisher) erstellt werden. Eine Publikation dient als Konfigurationsobjekt für das Replikationssystem von PostgreSQL. Sie legt fest, welche Änderungen in Form von WAL-Dateien aufgezeichnet und repliziert werden sollen. Die Publikationskonfiguration erlaubt es einzelne Tabellen auszuwählen, von welchen die Änderungen erfasst und an andere Systeme übertragen werden sollen.
Der sogenannte walsender-Prozess ist dafür verantwortlich, die logische Dekodierung des WAL mithilfe des pgoutput-Plugins zu starten (das pgoutput-Plugin muss in der PostgreSQL Datenbank vorab installiert werden). Es wandelt die Daten aus der internen Darstellung des WAL in das gewünschte Format um, das vom Verbraucher (Subscriber) gelesen werden kann. Das Plugin filtert die Daten gemäss der Publikationskonfiguration, wodurch nur einzelne Tabellen repliziert werden können.
Zu einer Publikation wird im Hintergrund automatisch auch ein Replication-Slot erzeugt. Der Replication-Slot stellt sicher, dass PostgreSQL die benötigten WAL-Dateien nicht automatisch entfernt, solange die Daten noch nicht repliziert wurden. Dadurch wird gewährleistet, dass die Datenintegrität erhalten bleibt und die Replikation ordnungsgemäss erfolgen kann.
Outbox-Pattern mit Debezium und PostgreSQL
Um das Outbox-Pattern zu implementieren, nutzt Debezium diese Replikationsfunktionalität von PostgreSQL. Ein eigens für diesen Zweck entwickelter Kafka-Konnektor, der PostgresConnector, wird mit dem Debezium-Plugin für Kafka-Connect ausgeliefert. Bei der Erstellung des Kafka-Konnektors übernimmt Debezium gleichzeitig die Einrichtung der Publication, Publisher der logischen Replikation, und des Replication-Slots. Der Kafka-Konnektor agiert als Subscriber und wird von der Publication über neue Einträge in der Outbox-Tabelle informiert.
Die Konfiguration und der Zustand der Kafka-Konnektoren wird auf Kafka selbst in dedizierten Topics gespeichert — ein separates Topic für die Konfiguration, eines für den Fortschritt und eines für den aktuellen Zustand.
Lösungen zu häufig auftretenden Fehlerquellen und Problemen
Mit dem Wissen um die Replikationsfunktionalität von PostgreSQL sind wir gut gerüstet, um im Fehlerfall richtig zu reagieren. Im Folgenden stellen wir einige hilfreiche Tools und Lösungen für häufig auftretende Fehlerquellen und Probleme vor. Anhand von vier Themenbereichen zeigen wir auf, wie die Fehlersuche vereinfacht werden kann und welche Massnahmen für einen reibungslosen Betrieb des Outbox-Patterns getroffen werden können.
1. Die Kafka-Konnektoren überwachen
Log-Level anpassen
Die Kafka-Konnektoren von Debezium schreiben Log-Dateien. Im normalen Betrieb ist der Log-Level der Konnektoren auf WARN oder sogar ERROR gesetzt. Bei der Fehleranalyse kann dieses Log-Level jedoch bei Bedarf angepasst werden. Am schnellsten geht das über die Kafka-Connect REST API. Die Kafka-Konnektoren müssen dafür nicht gestoppt werden — die Anpassung ist während der Laufzeit möglich. Mit folgendem Kommandozeilenbefehl kann der Log-Level für alle Konnektoren angepasst werden:
$ curl -s -X PUT -H "Content-Type:application/json" http://localhost:8083/admin/loggers/io.debezium.connector.postgres -d '{"level": "DEBUG"}'In diesem Beispiel gehen wir davon aus, dass Kafka-Connect lokal auf dem Port 8083 erreichbar ist. Falls DEBUG als Log-Level nicht ausreicht kann auch TRACE verwendet werden.
Redpanda installieren
Der Zustand der Kafka-Konnektoren kann über die Kafka-Connect API über die Konsole abgefragt werden:
$ curl http://localhost:8083/connectors
$ curl http://localhost:8083/connectors/my_connector/config
$ curl http://localhost:8083/connectors/my_connector/statusDie Interaktion über die Konsole ist jedoch umständlich und mühsam. Mit der Redpanda-Konsole können die Kafka-Konnektoren einfacher überwacht werden.
Über das UI kann entweder ein einzelner Task des Konnektors oder der gesamte Konnektor neu gestartet werden. So wird eine reibungslose Datenübertragung sofort wieder sichergestellt.
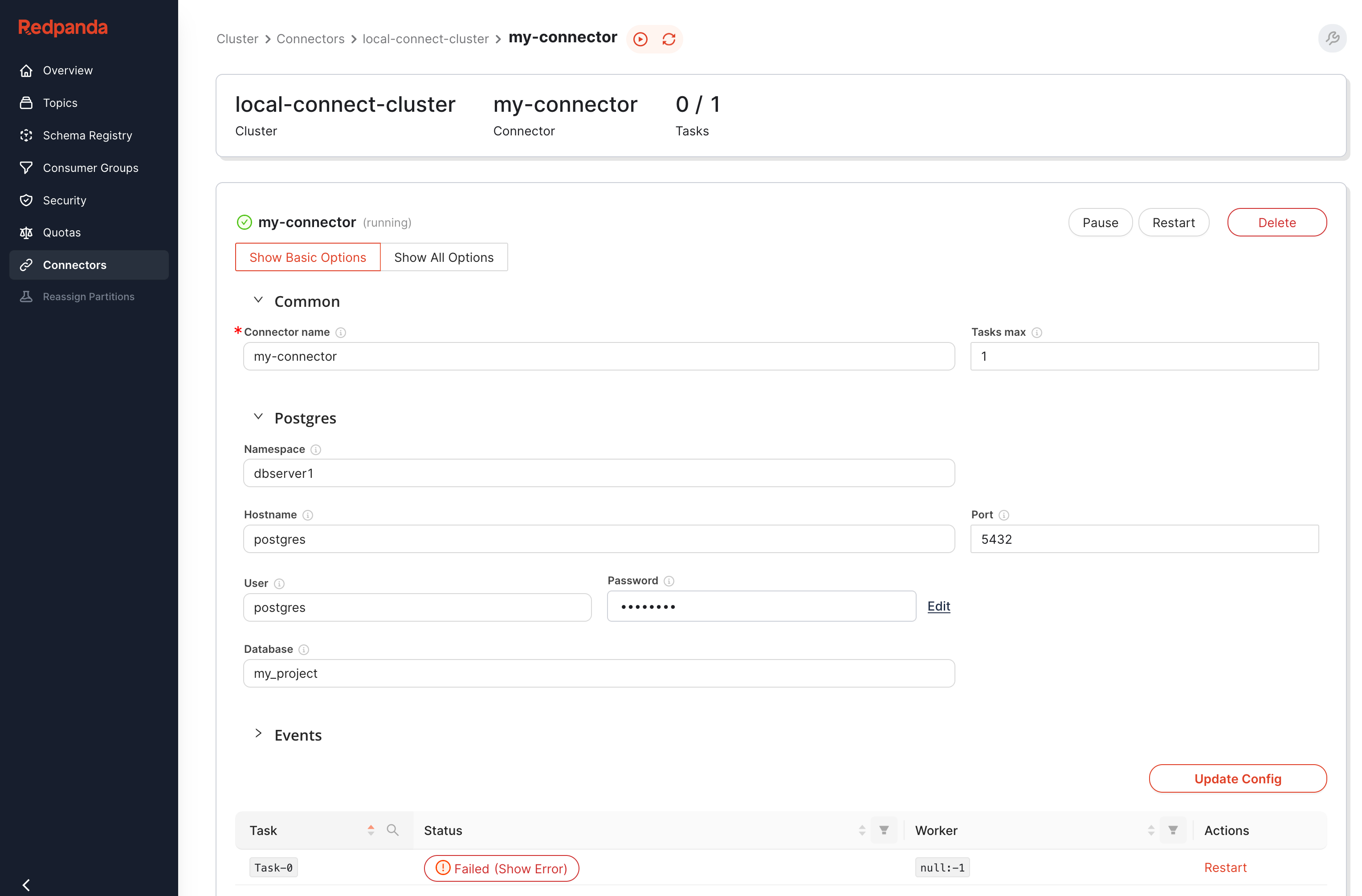
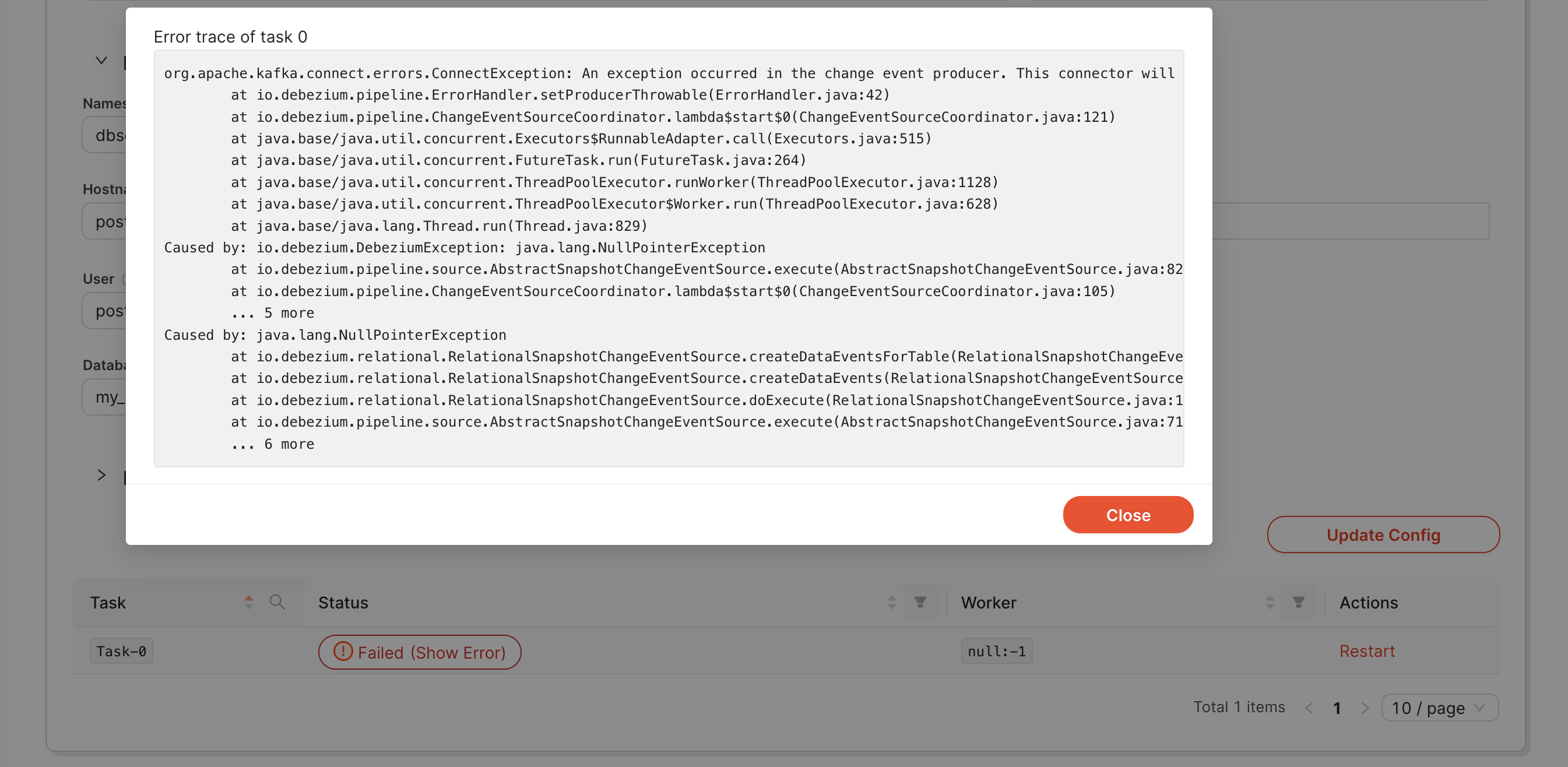
Dank der Redpanda-Konsole können die Konfigurationdetails von Konnektoren mühelos eingesehen werden, was eine verbesserte Kontrolle über die Konnektorkonfiguration gewährleistet. Darüber hinaus wird die Konsole genutzt, um potenzielle Probleme mit einem Konnektor zu identifizieren. Sollte ein Konnektor nicht mehr wie erwartet funktionieren, wird dies in der Konsole angezeigt. Die Fehlermeldung wird über ein Popup angezeigt, was die Fehleranalyse erheblich erleichtert.
2. PostgreSQL Datenbank korrekt konfigurieren
Um den Debezium Kafka-Konnektor zu erstellen, müssen sowohl die Datenbankverbindung als auch der Datenbankserver selbst korrekt eingerichtet sein.
Berechtigungen
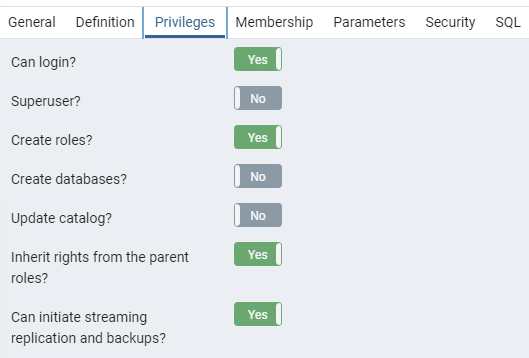
Caused by: org.postgresql.util.PSQLException: FATAL: must be superuser oder replication role to start walsenderFür die Verbindung zur Datenbank muss der verwendete Datenbankbenutzer über die notwendigen Berechtigungen verfügen. Im Fall von PostgreSQL und Debezium wird die Replikationsfunktionalität von PostgreSQL genutzt. Daher benötigt der Benutzer die Replikationsrolle. Die Rollen jedes Benutzers können über ein SQL-Skript oder Tools wie pgAdmin abgefragt werden:
SELECT
r.rolname,
r.rolreplication
FROM pg_catalog.pg_roles r
WHERE r.rolname !~ '^pg_';Alternativ können die Benutzerrollen auch über den pgAdmin abgerufen werden.
PostgreSQL-Settings
Neben den Berechtigungen können auch fehlerhafte Einstellungen am PostgreSQL-Datenbankserver selbst zu Problemen führen. Bei der Installation von PostgreSQL sind bestimmte Konfigurationswerte bereits voreingestellt. Wenn es nicht möglich ist, einen Debezium-Konnektor zu erstellen, könnte dies darauf hindeuten, dass die Standardkonfiguration nicht ausreichend ist.
Ein solcher Konfigurationswert ist die maximale Anzahl von Replication-Slots, die standardmässig auf nur zehn begrenzt ist. Diese Begrenzung wird durch den Konfigurationswert max_replication_slots festgelegt und bestimmt, wie viele Replication-Slots gleichzeitig erstellt werden können. Somit kann Debezium auch nur maximal zehn Kafka-Konnektoren gleichzeitig erstellen. Falls mehr Konnektoren notwendig sind, muss diese Konfiguration zwingend erhöht werden.
Zusätzlich muss auch der Konfigurationswert max_wal_senders erhöht werden. Dieser Wert legt fest, wie viele WAL-Sender gleichzeitig ausgeführt werden können, was wiederum die Anzahl der möglichen Replikationen auf einer Datenbank beschränkt.
Die aktuellen Konfigurationswerte einer PostgreSQL-Installation können über einen SQL-Befehl abgerufen werden. Änderungen an diesen Konfigurationen können nur von Administratoren vorgenommen werden und erfordern zwingend einen Neustart der Datenbank.
SELECT *
FROM pg_settings
WHERE name = 'max_replication_slots' OR name = 'max_wal_senders';3. Mit den Replikationskomponenten von PostgreSQL interagieren
Wir konzentrieren uns nun auf die Situation, in der Events in der Outbox-Tabelle landen, aber nicht erfolgreich auf Kafka publiziert werden. Um diesem Fehlverhalten auf den Grund zu gehen, müssen wir das Zusammenspiel von Publikation und Replication-Slots untersuchen.
Ein wichtiger Unterschied zwischen Publikation und Replication-Slot ist, auf welcher Ebene sie existieren. Eine Publikation ist ein Objekt in PostgreSQL, das auf Datenbankebene existiert. Sie wird pro Datenbank erstellt und definiert, welche Tabellen oder Schemata repliziert werden sollen. Im Gegensatz zur Publikation existiert ein Replication-Slot auf der Ebene der gesamten Datenbankinstanz.
Überprüfung der Publikation
Wenn Events nicht wie erwartet auf Kafka publiziert werden, liegt möglicherweise ein Problem mit der Publikation-Konfiguration in PostgreSQL vor. Über ein SQL-Skript kann der Zustand der Publikation überprüft werden. Da die Publikation nur auf der Datenbankebene existiert, muss zwingend die entsprechende Datenbank ausgewählt sein, bevor dieses Skript ausgeführt wird.
SELECT * FROM pg_publication;Falls erforderlich, kann die Publikation gelöscht und neu erstellt werden.
delete from pg_publication where pubname = 'dbz_publication';Überprüfung des Replication-Slots
Ein weiterer möglicher Grund für das Problem könnte ein fehlerhafter Replication-Slot sein. Das folgende SQL-Skript gibt den Zustand des Replication-Slots aus.
SELECT * FROM pg_replication_slots;Die Replication-Slots existieren auf der Ebene der Datenbankinstanz. Darum gibt dieses SQL-Skript alle Replication-Slots der gesamten Datenbankinstanz aus.
Falls der Replication-Slot einen Fehler aufweist, kann dieser gelöscht werden.
SELECT pg_drop_replication_slot('debezium_my_project');Warum können Publikationen und Replication-Slots einfach gelöscht werden?
Ein Debezium-Konnektor speichert seinen Zustand in einem sogenannten Offset-Topic. Das Offset-Topic ist ein spezielles Kafka-Topic, in dem der Konnektor Informationen über den Fortschritt der Datenänderungen speichert. Genauer gesagt speichert der Konnektor die aktuelle Position in den WAL (konkret die Log-Sequence-Number LSN), die den Fortschritt der Datenverarbeitung in der Quelldatenbank angibt.
Mithilfe des Offset-Topics kann der Konnektor bei einem Neustart oder einer Unterbrechung an der letzten verarbeiteten Datenänderung fortzusetzen und verpasst dadurch keine Datenänderungen. Das Offset-Topic wird vom Debezium Kafka-Konnektor automatisch erstellt und verwaltet. Es ist wichtig, dass dieses Topic nicht gelöscht wird, da sonst der Konnektor seinen Fortschritt verliert und von vorne beginnen muss.
Kafka-Konnektor neu starten
Damit die Publikation und der Replication-Slot wieder korrekt aufgesetzt werden, muss der Kafka-Konnektor neu gestartet werden. Über die Redpanda-Konsole lässt sich das am einfachsten bewerkstelligen.
4. Den Datenbankspeicher freigegeben
Wir haben gelernt, dass die Replikationsfunktionalität von PostgreSQL auf WALs basiert. Diese WAL-Dateien benötigen Speicherplatz. PostgreSQL löscht diese WAL-Dateien selbst, sobald sie nicht mehr benötigt werden.
Replication-Slots stellen sicher, dass keine WAL-Datei gelöscht wird, die noch benötigt wird. Wenn über einen längeren Zeitraum keine Einträge in die Outbox-Tabelle geschrieben werden, bleibt der Replication-Slot auf den alten WAL-Einträgen stehen. Dadurch wird verhindert, dass WAL-Dateien gelöscht werden, um Speicherplatz freizugeben.
SELECT
slot_name,
pg_walfile_name(restart_lsn) AS wal_file,
pg_wal_lsn_diff(pg_current_wal_lsn(), restart_lsn) AS age
FROM pg_replication_slots;Dies geschieht, wenn für einen Kafka-Konnektor keine neuen Events generiert werden. Der Replication-Slot des Kafka-Konnektors zeigt dann immer noch auf eine alte Position in der WAL-Datei, wodurch diese nicht freigegeben werden kann. Testsysteme sind davon häufiger betroffen, da einige Dienste nicht so intensiv genutzt werden wie andere.
Damit PostgreSQL den Speicherplatz wieder freigeben kann, muss lediglich sichergestellt werden, dass ein neuer Event generiert wird. Dafür kann entweder manuell ein Event publiziert werden: Ein Dummy-Eintrag in der Outbox-Tabelle löst den Debezium-Konnektor aus. Dadurch aktualisiert der Replication-Slot seine Position in der WAL-Datei, wodurch die veralteten WALs freigegeben und gelöscht werden können.
Dieses manuelle Verfahren ist etwas mühsam. Um dieses Problem zu umgehen, wird in unseren Projekten periodisch (z.B. stündlich oder täglich) von der Applikation ein Heartbeat-Event generiert. Damit stellen wir sicher, dass der Replication-Slot immer auf eine aktuelle WAL-Datei zeigt und somit alte gelöscht werden können. Der Heartbeat-Event kann auch zu Überwachungszwecken verwendet werden.
